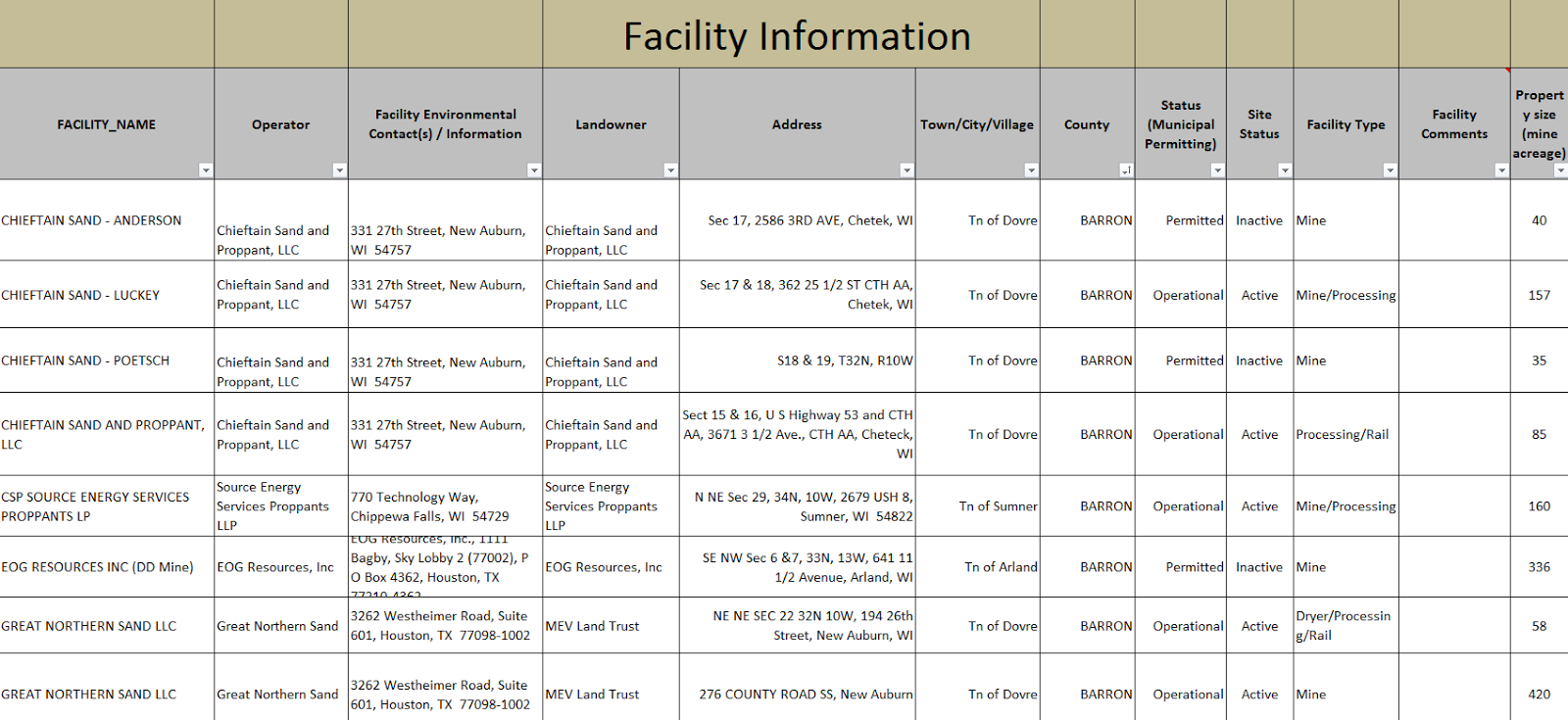
Objective:
Road damage caused by transport of sand via trucks from mines to rail terminals is a concern many Wisconsin communities have. The weight from these trucks can have impacts on the amount and frequency of road maintenance necessary to keep the roads safe for travelers which influences the dollar amount communities pay for this maintenance. Although some costs of road maintenance can be lessened through agreements between county governments and mining companies such as the Road Upgrade Maintenence Agreement (RUMA), it is critical to understand the base impact these mining companies could have on the road systems. In 2013, it was estimated that each year, mining companies in Wisconsin would transport 40 million tons of frac sand out of Wisconsin via trucks and rail cars (Hart, Adams, and Schwartz, 2013). This would undoubtedly heavily impact roadways for county residents as much of this sand would be trucked via rural roadways to railways. The video below shows a 40-minute time lapse of trucks transporting sand to and from a mine near Bloomer, Wisconsin and demonstrates just how much sand is transported from these sand mines.
Some costs can be mitigated by locating which routes would be the most efficient route between mines and rail terminals for the trucks to transport the frac sand. Utilizing Network Analysis tools is a great way to investigate and plan these efficient routes.
The objective of this lab was to introduce Network Analysis as a means of logistical planning. In this lab, I utilize python scripter to prepare our data from ESRI street map USA and the mine locations from the DNR mentioned in the previous geocoding activity. I use network analysis tools in model builder to find the most efficient routes between mines and rail terminals in terms of distance and to calculate a hypothetical cost to each county with data set arbitrarily by our professor.
Methods
Preparing Data Using Python
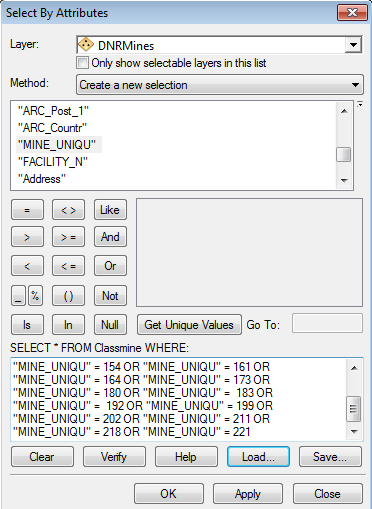
I began this lab by preparing the ESRI street map data in PyScripter. Through this script, I write and run SQL statements to select all active mines that have the word "mine" and lack the word "rail" in the facility type. This selection contains only the mines that are currently active, are the mine portion of the company, and lack a rail terminal within the mine facility, thus having a potential impact on local roads. After creating feature layers from these selections, I select mines within the state of Wisconsin and remove mines that are within 1.5km of a railway. More information on the script and a screen shot of the script itself can be found in my Python Script page listed as "Python Scripting Activity II: Network Analysis Data Preparation" (here).
Calculating Routes Using the Closest Facility Tool
I imported the python script feature class result (mines within Wisconsin that are 1.5km away from rail terminals), ESRI street map data that consisted of a network of streets, rail terminals to begin calculating routes between mine facilities and rail terminals. Using the Closest Facility tool in the Network Analysis toolbar, I loaded the locations with the rail terminals as the facilities and the mines as the incidents. I then solved the to find the closest rail terminal to each mine. The tool successfully resulted with each of the 44 mines (incidents) and their closest rail terminal (facilities) correctly located (Fig. 1) with a route calculated between each mine and its closest rail terminal (Fig. 2).
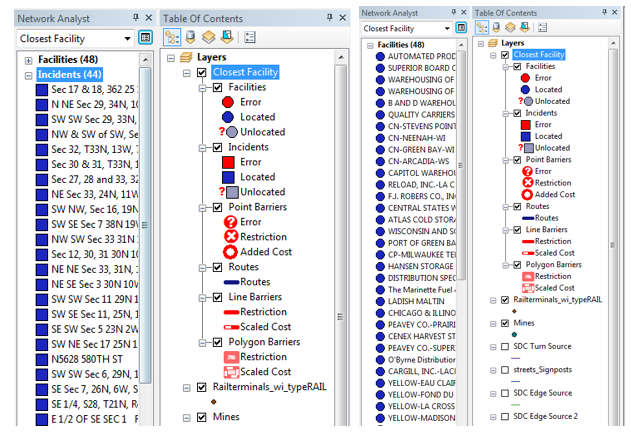 |
| Fig. 1: Screenshot of the Network Analyst Window showing result of the Closest Facility Tool. |
 |
| Fig. 2: Result of the Closest Facility Tool in the Network Analysis toobar displaying routes between each mine and its closest rail terminal. |
Using Model Builder to Calculate Hypothetical Costs
After utilizing the Network Analysis Toolbar to calculate the closest facilities and most efficient routes, I began using model builder to estimate the distance traveled in each county by frac sand trucks and to estimate the cost of road maintenance for each county using the hypothetical data given to the class by the professor for number of trucks, for each route and the cost per mile for road maintenance.
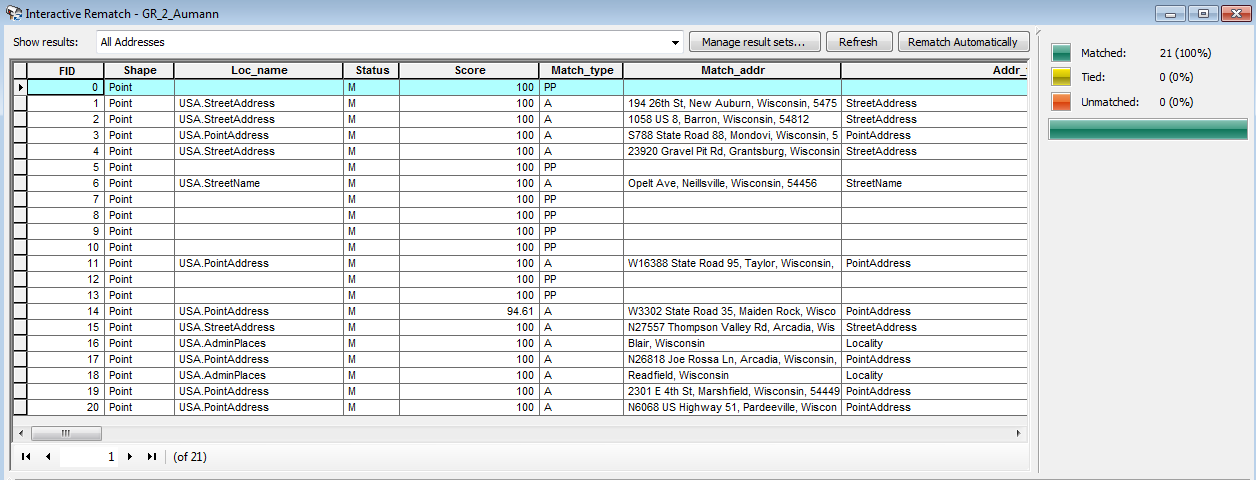
I started model builder with rerunning the Closest Facility tool to recalculate routes merely for practice in model builder (Fig. 3). This step was unnecessary as the results from the Closest Facility tool had already been exported into the map as feature classes for facility, incidents, and routes. However, it was good measure to compare the results from the previous run of the Closest Facility tool and the results from the model builder. The resulting incidents, facilities, and routes from the model builder was consistent with the manual Closest Facility tool results.
To calculate closest facilities in Model Builder, I added the Make Closest Facility Layer tool with the ESRI street data as the input. I then specified my mines feature class as incidents by adding the Add Location tool. I added another Add locations tool to specify my rail terminal feature class as the facilities. The Solve tool was added to solve the closest facility tool and calculate routes.
After generating closest facilities, I added the Select Data tool to select route data from the closest facility output. I then added the Copy Features tool to create this selected route data a new feature class which I appropriately named "Routes." I projected the outcome to NAD 1983 UTM Zone 15N to match the rest of the data layer using the Project tool.
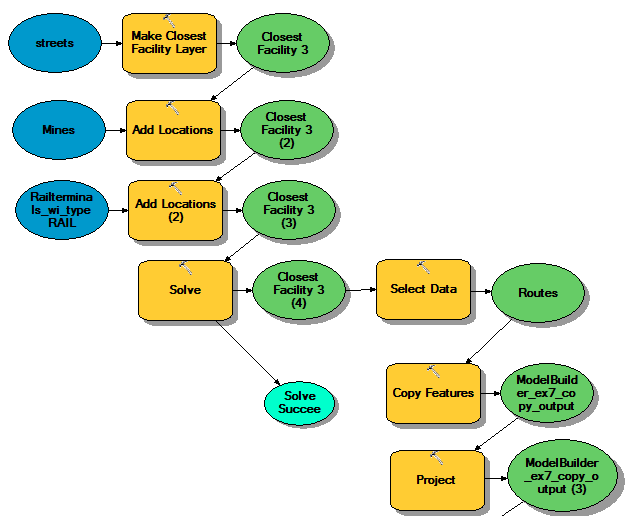 |
| Fig. 3: Model Builder process for calculating routes and projecting the resulting routes feature class into an appropriate projection. |
From here, I started the process of calculating the distance traveled and hypothetical costs per county. I began by projecting the county boundaries feature class into the same projection as the previous outputs and intersecting this result with the projected routes feature class (Fig. 4).
 |
| Fig. 4: Projecting and intersecting the county boundary feature class with the projected routes feature class in Model Builder. |
 |
| Fig. 5: Summarizing route length, adding distance field, and calculating the distance field in Model Builder. |
 |
| Fig. 7: Calculate Field window displaying calculation expression for distance traveled per county. |
To calculate the cost, I added another Summary Statistics tool to the intersect output to summarize route length by county, just as I had done before adding the distance field. I used the Add Field tool again to add a field for cost, titled "Cost." Finally, I calculated the field with the expression as the [SUM_Shape_Length] * 50 * 2 * 0.000621371 * 2.2 / 100 with the (2.2/100) sequence representing the 2.2 cents it hypothetically costed to maintain a mile of road length. The final Model Builder process can be seen in Figure 8.
 |
| Fig. 8: The full Model Builder process. |
Results
The result of the Calculate Field tool for distance yielded an attribute table with the Distance in miles field containing values of total miles traveled by frac sand trucks to and from mines and rail ways in each county (Fig. 9). I displayed the distance in a bar graph created in ArcMap (Fig. 10). The Calculate Field tool appropriately calculated the cost per county for the distance traveled by frac sand trucks within the area and the result is displayed in an attribute table (Fig. 11) and in a graph created in ArcMap (Fig.12).
 |
| Fig. 9: Distance in miles listed as "Dist_miles" field in the Model Builder output. |
 |
| Fig. 10: Distance Traveled in each county. |
 |
| Fig. 11: Cost per county listed as the "Cost" field in the Model Builder output. |
 |
| Fig. 12: Cost per county. |
Each county varied greatly in hypothetical potential cost in road maintenance. Some counties, such as Buffalo and Pepin would only pay between $2.80 and $27.11 while other counties, like Chippewa and Eau Claire would need to pay between$277.67-$613.61 (Fig. 13).
 |
| Fig. 13: Final map depicting the costs for road maintenance by county. |
Discussion
In Fig. 12, you can see that the counties with the highest hypothetical cost for road maintenance are Chippewa ($613.14), Eau Claire ($385.22), and Barron ($371.72). If this data were taken from a real data set for number of trucks and the cost for road maintenance, these counties would need to be aware of the impact the mining companies have on their local roads and may want to consider an agreement plan between mining companies and the government much like RUMA. However, all counties containing mine to rail routes should be aware of potential impacts on their road maintenance. At the beginning of the lab, before I had removed rail terminals outside of Wisconsin, I noticed there were a couple terminals that may be even closer to some of the mines along the border of Wisconsin. If I were to do the lab again, it may be wise to keep rail terminals in Minnesota and Wisconsin to see if there could be a more efficient way to transport the sand. However, this would have potential to raise issues between the two states. Because the closest Wisconsin rail terminal to the mine located in Burnett County has a most efficient route through the state of Minnesota, this may already be a problem without considering rail terminals in Minnesota for closest facilities (Fig. 13).
Conclusion
In this lab, we used PyScripter to set up queries and create feature layers and used Network Analysis tools in the Network Analysis toolbar as well as in Model Builder to calculate the closest facilities and most efficient routes as well as hypothetical distances traveled and cost of road maintenance per county due to frac sand trucking. These Network Analysis tools can be and are currently used by many businesses to plan logistics for shipping products. For this lab, however, since our data was only hypothetical, I cannot derive any true conclusion about frac sand transport and the most efficient routes and costs to counties. Though this is a useful skill that other businesses and research projects may require.
Sources
Hart, M. V., Adams, T. & Schwartz, A. (2013). Transportation Impacts of Frac Sand Mining in the MAFC Region: Chippewa County Case Study. In Mid-America Freight Coalition. Retrieved: November 19, 2013, From http://midamericafreight.org/wp-content/uploads/FracSandWhitePaperDRAFT.pdf.